

Authors:
(1) Abraham Owodunni, Intron Health, Masakhane, and this author contributed equally;
(2) Aditya Yadavalli, Karya, Masakhane, and this author contributed equally;
(3) Chris Emezuem, Mila Quebec AI Institute, Lanfrica, Masakhane, and this author contributed equally;
(4) Tobi Olatunji, Intron Health and Masakhane, and this author contributed equally;
(5) Clinton Mbataku, AI Saturdays Lagos.
Table of Links
4 What information does AccentFold capture?
5 Empirical study of AccentFold
6 Conclusion, Limitations, and References
4 What information does AccentFold capture?
In this section, we delve into an exploratory analysis of the t-SNE visualizations for all the accents in AccentFold. Our aim is to gain a deep understanding of the intricate connections and patterns that emerge among these diverse accents. The t-SNE visualizations of the accent in AccentFold can be found in Figures 2, 3, 4. We also present some more Figures (8, 9, 10, 11) in the Appendix.
Language Families: Figure 10 presents a t-SNE visualization of the learned accent embeddings, where color coding is utilized to distinguish language families, and varying levels of transparency ensure distinct colors for each accent. Each point in the figure corresponds to an accent embedding obtained through AccentFold, allowing us to convey two pieces of information: the distribution of accents and their respective language families.
Through an exploratory analysis of Figure 10, we observe that the accent embeddings tend to
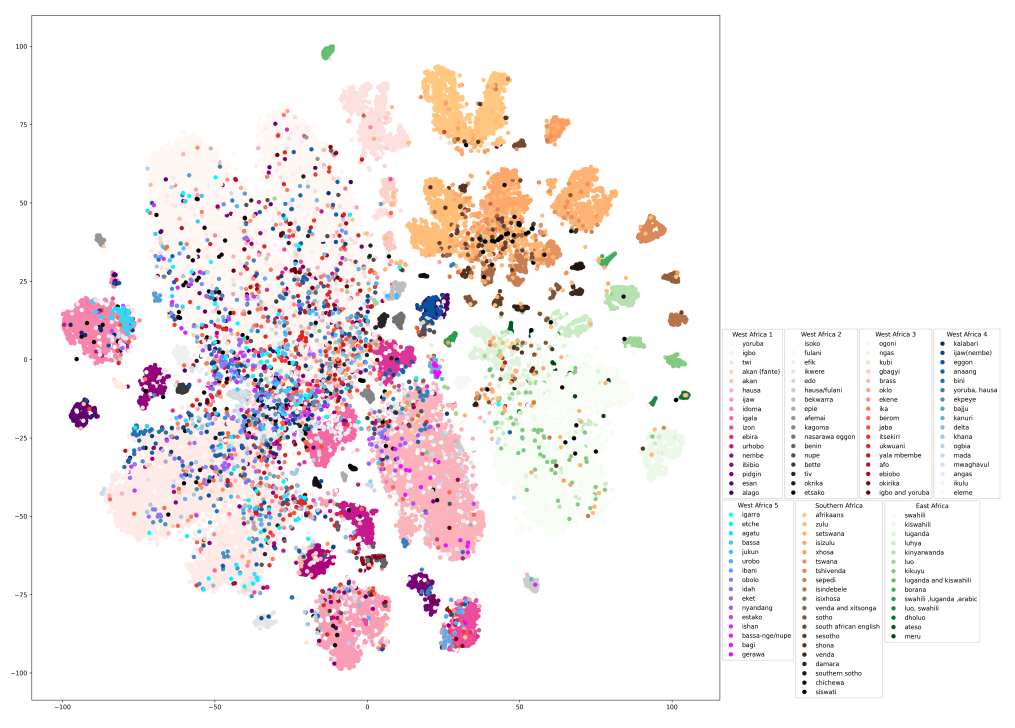
group together (forming what we refer to as “accent folds”) based on language family similarities. Language families represent the genetic connections between languages, as they consist of languages that descended from a common ancestor (Comrie, 1987). These language families exhibit syntactic, phonological, and morphological relationships (de Marneffe and Nivre, 2019). Based on these observations, we hypothesize that AccentFold captures linguistic regularities within accents.
Geographically Consistent Clusters: Although the majority of the data comes from Nigeria, Figure 3 plots all test samples with their country labels showing spatial relationships between countries. The t-SNE plots generally align with geographical disposition, accents from Nigeria (Orange) are closer in vector space to Ghana (blue) but further from Kenya, Uganda, Rwanda, and South Africa likely reflecting the distinct languages spoken across these countries. However, where similar languages (e.g. Swahili) are spoken across countries (e.g. Botswana and South Africa), the spatial distinction is less apparent. Uganda, Kenya, and Tanzania cluster together while Botswana and South Africa cluster together and Rwandan embeddings fall between both regions. This demonstrates that the learned embeddings do encode some geographical information extracted entirely from speech and accent labels.
Accent disposition: In Figure 8, Ghanaian accents - Twi and Akan (Fante), cluster closer together and are distinct from Nigerian neighbors. South African accents Zulu, Afrikaans, and Tswana cluster together. Similarly, Kinyarwanda, Luganda, Luganda, Swahili, Luhya and other East African accents cluster together. In Nigeria, Northern accents Hausa and Fulani cluster together and are closer to middle belt accents than South-Eastern and South-Western Nigerian accents. Accents spoken in South-Eastern Nigeria, which make up the majority of West African accents in this dataset, represent the collection of embeddings with indistinguishable margins, representing the close relationship between these accents.
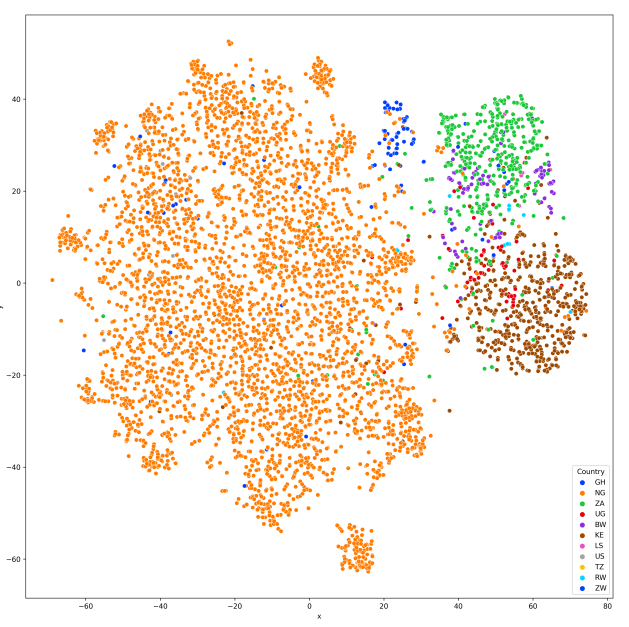
Peripheral West African Clusters: Figure 3 shows a distinct pattern in the Nigerian accents. There are 10 distinct peripheral subclusters surrounding a more homogenous core. These may represent accents with very distinct linguistic or tonal characteristics from various parts of the country. Some of these accents include Okirika, Bajju, Brass, Agatu, Eggon, Mada, Ikulu Hausa and Urobo.
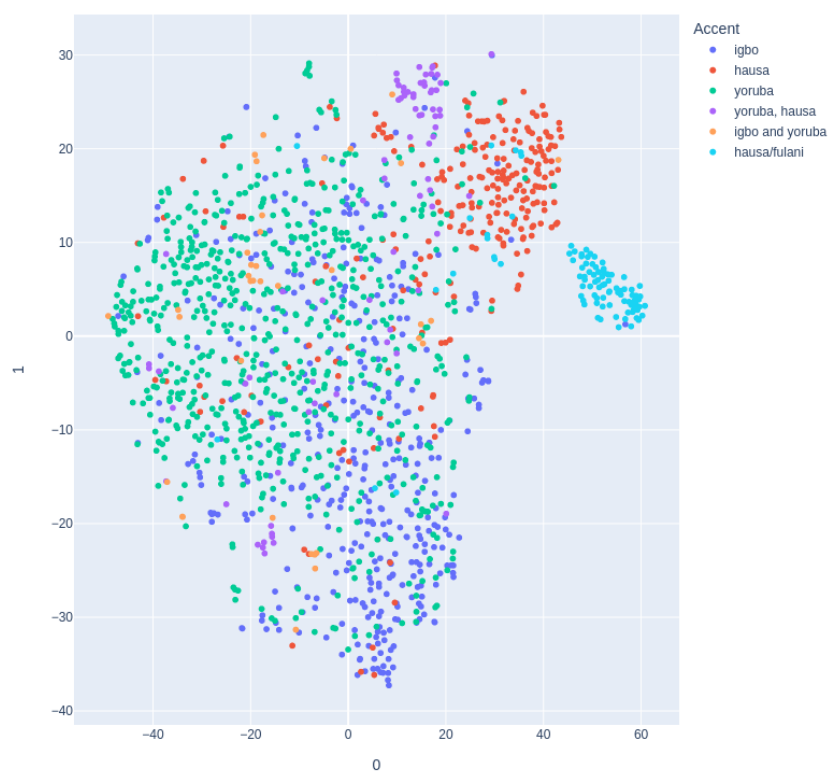
Dual Accents: Figure 4 shows a really interesting phenomenon with speakers with self-reported dual accents. Sample embeddings for dual accents "Igbo and Yoruba" (orange) fall between the Igbo (blue) and Yoruba (green) clusters. Although Yoruba (green) and Hausa (red) are very distinct accents, speakers with dual accents (purple) fall somewhat between both clusters. This trend is consistent with Yoruba/Hausa and Hausa/Fulani accents.
4.1 Contrasting with the Ethnologue
According to Ethnologue (Campbell, 2008) there are 7,151 living human languages distributed in 142 different language families, 6 of which are assigned to Africa, based on historically accepted language ancestry. Although the empirically learned embeddings generally support this classification, they reveal 2 interesting possibilities that remain uncharacterized by the Ethnologue.
Kwa-Bantu Relationship: Although the Ghanaian Kwa languages are traditionally separated from the Bantu languages in South Africa and are geographically very distant, our embeddings suggest they may be more similar than earlier proposed and possibly share similar ancestry. This line of reasoning is supported by Güldemann (2018) reclassification of African languages.
Niger-Congo Subfamilies. Although there have been attempts to better categorize the large NigerCongo family, Güldemann (2018)’s work, based on basic classificatory units and genealogical relations, rethinks traditional classification. The spatial disposition shown in Figure 9 also suggests possible sub-families based on speech representations empirically learned by optimizing the MTL objective function.
4.2 Accent Normalization and Re-identification
User reported accents are sometimes noisy. In the Afrispeech dataset, we encountered 4 strange accent labels where their groupings shed more light on possible true accent labels. 11 speakers located in Nigeria reported their accent as “English”. Although the centroid for this group is closest to the “Berom" accent, all samples for this group fall within clusters occupied by speakers from Southeastern Nigeria. Another group of 20 speakers reported a “pidgin” accent. Embedding for speech for speakers are nearest to clusters from Ijaw, Delta, Edo, and other Nigerian accents where pidgin accent is prevalent. 2 speakers self-identified their accents as “South African English”. However embeddings are closest to Afrikaans speakers. Embeddings for a group of “Portugese” speakers located in South Africa also fall very close to Zulu and Tswana, both south African accents. Embedding/Accent distances were also very valuable with normalizing dialects or misspelled accents for example “luo” and “dholuo”, “Twi” and “Akan”, “kiswahili” and “swahili” and many others.
This paper is available on arxiv under CC BY-SA 4.0 DEED license.