

Authors:
(1) Abraham Owodunni, Intron Health, Masakhane, and this author contributed equally;
(2) Aditya Yadavalli, Karya, Masakhane, and this author contributed equally;
(3) Chris Emezuem, Mila Quebec AI Institute, Lanfrica, Masakhane, and this author contributed equally;
(4) Tobi Olatunji, Intron Health and Masakhane, and this author contributed equally;
(5) Clinton Mbataku, AI Saturdays Lagos.
Table of Links
4 What information does AccentFold capture?
5 Empirical study of AccentFold
6 Conclusion, Limitations, and References
5 Empirical study of AccentFold
5.1 Problem Formulation
In this empirical study, we set out to understand how informative the accent folds are for accentlevel zero shot ASR performance. To achieve this, we designed our experimental task as follows: Assume we have the below oracle data set generator:

5.2 Experimental Setup

Fine-tuning Details: We use a pre-trained XLSR model (Conneau et al., 2020) for our experiments. The XLSR model extends the wav2vec 2.0 (Baevski et al., 2020) model to the cross-lingual setting and was trained to acquire cross-lingual speech representations through the utilization of a singular model that is pre-trained using raw speech waveforms from various languages. The fact that this model is cross-lingual makes it a good fit for our experiments.
During the fine-tuning of our pre-trained model, we follow the hyperparameter settings of Olatunji et al. (2023a). These include setting the dropout rates for attention and hidden layers to 0.1, while keeping the feature projection dropout at 0.0. We also employ a mask probability of 0.05 and a layerdrop rate of 0.1. Additionally, we enable gradient checkpointing to reduce memory usage. The learning rate is set to 3e-4, with a warm-up period of 1541 steps. The batch sizes for training and validation are 16 and 8, respectively, and we train the model for ten epochs.
For each of the 41 target accents, we finetune our pre-trained model on its corresponding dataset and evaluate the word error rate on the test set comprising audio samples containing only the target accent. We run all our experiments using a 40GB NVIDIA A100 SXM GPU, which enables parallel use of its GPU nodes.
Evaluation procedure: It is important to note that although the training dataset size Nk depends on the target accent aOOD in consideration, the test set used to evaluate all our experiments is fixed: it comprises the samples from the test split of the Afrispeech-200. Using Figure 1 the test set are samples from all the 108 accents of the test split. By keeping the test set constant, we can assess the model’s performance on our intended accent aOOD in an out-of-distribution (OOD) scenario. This is because the training and development splits do not include any audio-speech samples from these accents. Additionally, this procedure enables us to evaluate the model’s capacity to generalize to other accent samples, resulting in a highly resilient evaluation.
5.3 Results and Discussion
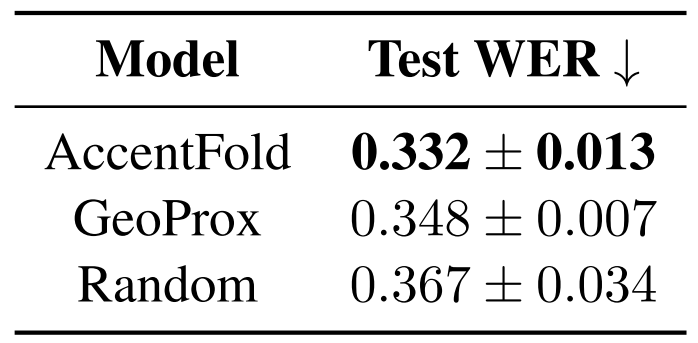
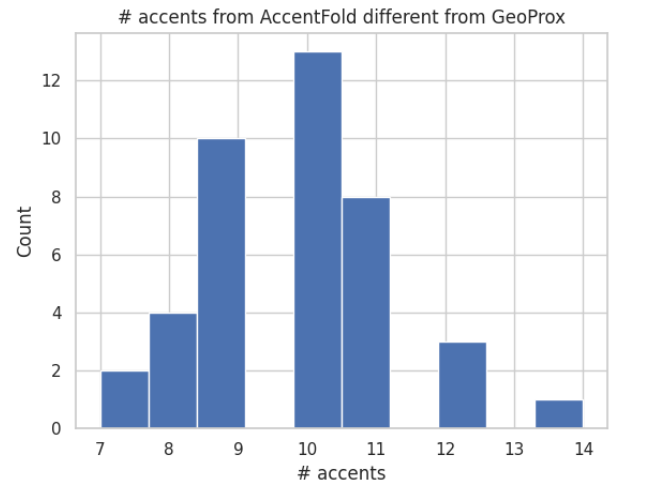
Table 2 presents the results of a test Word Error Rate (WER) comparison between three different approaches for subset selection: AccentFold, GeoProx, and random sampling. The table displays the average and standard deviation of the WER values over the 41 target OOD accents. The results show that the AccentFold approach achieves the lowest test WER of 0.332 with a standard deviation of 0.013. In contrast, the random sampling approach yields the highest test WER of 0.367 with a larger standard deviation of 0.034. GeoProx, which uses real-world geographical proximity of the accents, performs better than random sampling but still under-performs when compared to AccentFold. To better understand this, we investigate the accents selected by AccentFold and GeoProx and analyse their non-overlapping accents in Figure 6. The histogram reveals that many of the accents selected by AccentFold for any given target OOD accent, aOOD, are not necessarily those geographically closest to aOOD. This insight suggests that the learned embeddings in AccentFold encompass much more than geographical proximity of accents.
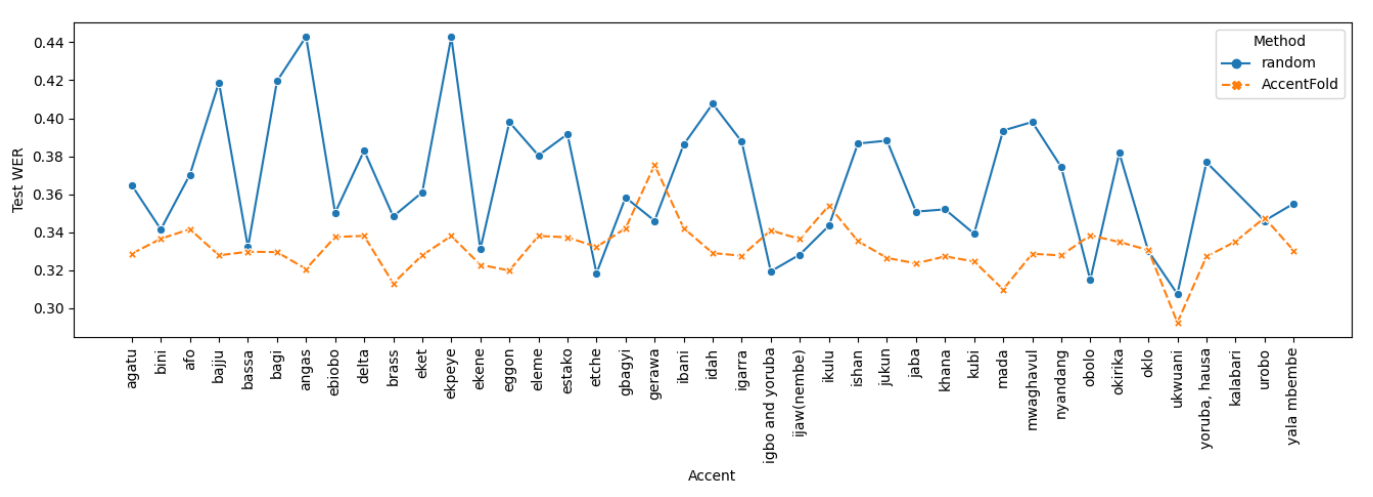
Figure 5 visualizes the test WER obtained by AccentFold and random sampling for each of the 41 accents. We see that in majority of the accents, AccentFold leads to improved performancte in terms of WER compared to random sampling. These findings indicate that AccentFold effectively captures linguistic relationships among accents, allowing for more accurate recognition of the target OOD accent when used to build the fine-tuning dataset. This demonstrates the usefulness of leveraging linguistic information and accent embeddings provided by AccentFold in the context of automatic speech recognition tasks.
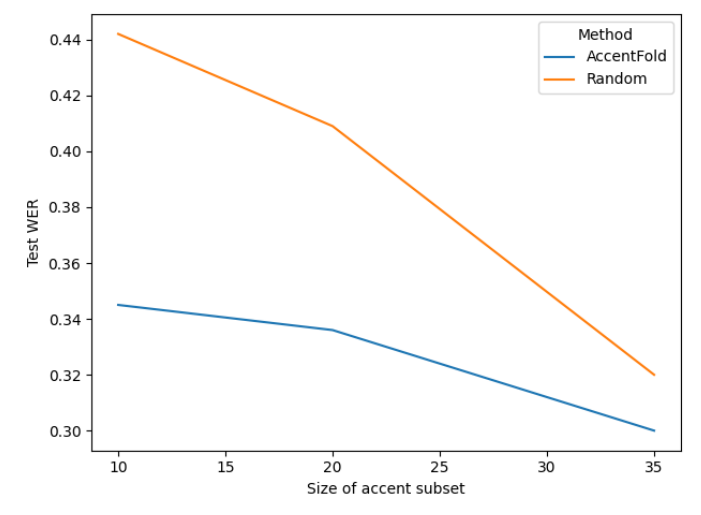
We notice a pattern, as shown in Figure 7, where increasing the value of s, which corresponds to a larger training dataset size Nk, results in minimal variation in the selection of accent subsets. This convergence of test WER implies that as the sample size increases, the specific choice of accent subsets becomes less influential in determining the performance.
This paper is available on arxiv under CC BY-SA 4.0 DEED license.