

The Big Spotify Shakeup: Founder/CEO Daniel Ek Steps Down, Co-CEOs Norström and Söderström Step Up
30 Sept 2025
The Spotify universe just got a massive leadership shakeup. On September 30, 2025, founder and CEO Daniel Ek announced he’s officially stepping down.
How This AI Model Generates Singing Avatars From Lyrics
7 Aug 2025
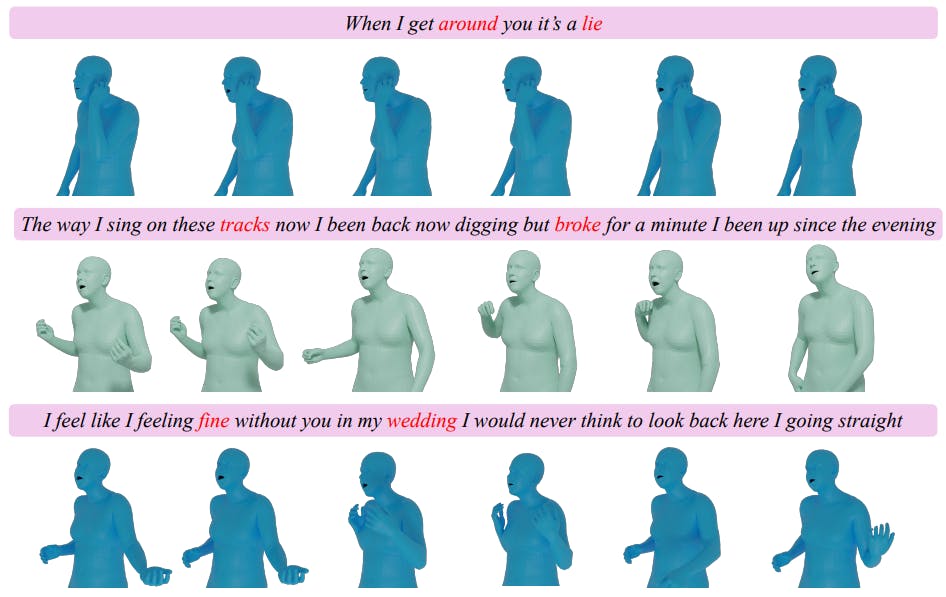
Discover how this AI system generates rapping avatars—synthesizing motion, voice, and lip sync from text using cutting-edge VQ-VAE models.

Joint Modeling of Text, Audio, and 3D Motion Using RapVerse
7 Aug 2025
An AI model that turns lyrics into 3D rap performances with synced vocals and motion. Powered by RapVerse. Welcome to the future of music creation.

This AI Turns Lyrics Into Fully Synced Song and Dance Performances
7 Aug 2025
An AI model that generates synchronized vocals and full-body motion from text—outperforming cascaded systems with smarter joint training.
Text-to-Rap AI Turns Lyrics Into Vocals, Gestures, and Facial Expressions
7 Aug 2025
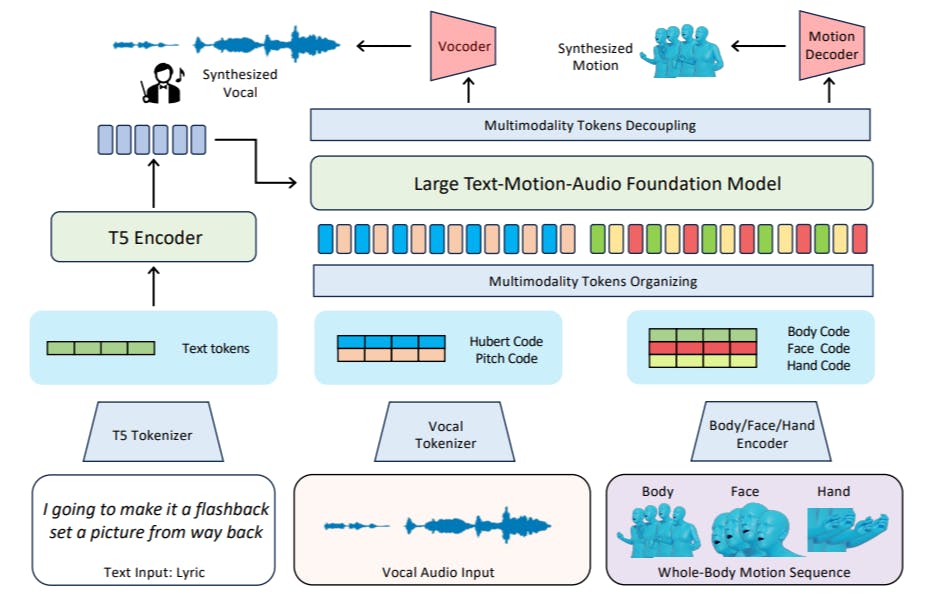
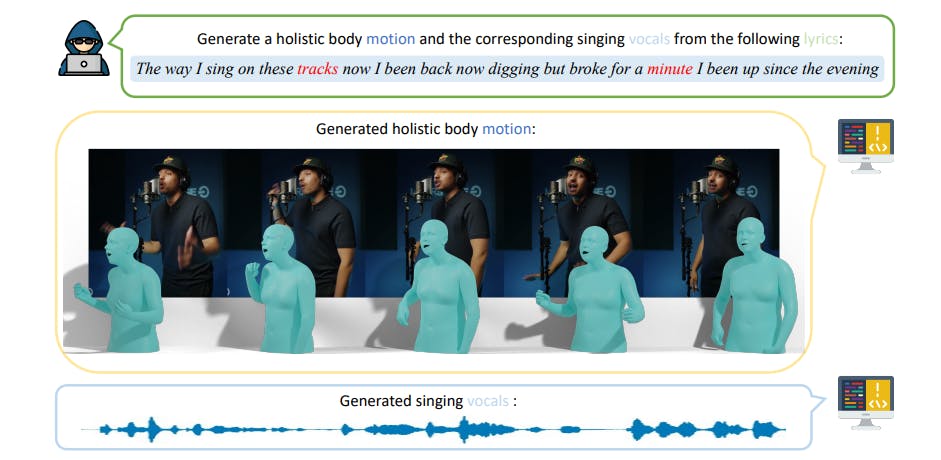
Generate rap vocals, gestures, and facial expressions from lyrics using a unified AI model built on the RapVerse dataset.
A Multimodal Dataset for Synthesizing Rap Vocals and 3D Motion
7 Aug 2025
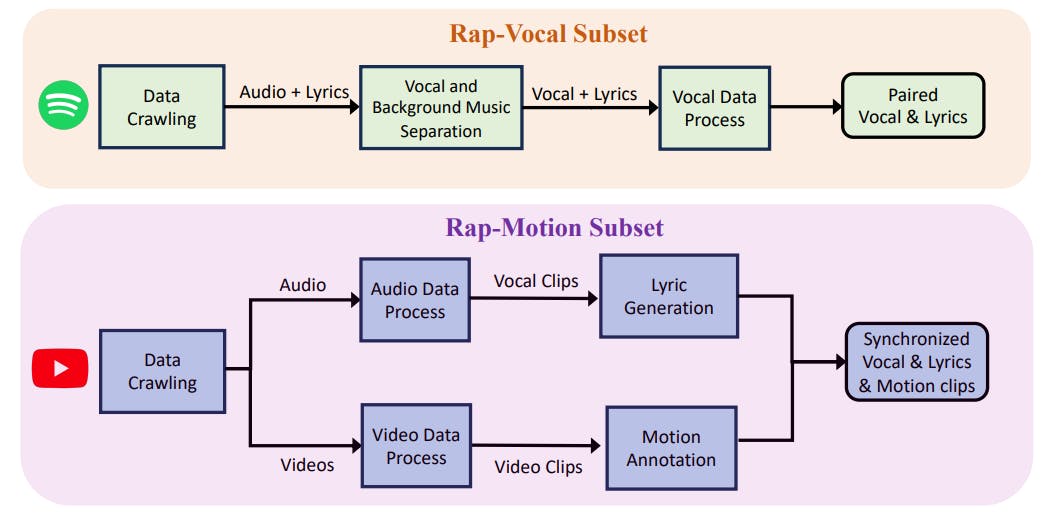
A new dataset for AI-generated rap: synchronized vocals, lyrics, and full-body motion from real performances. Meet RapVerse.
The RapVerse Dataset: A New Benchmark in Text-to-Music and Motion Generation
7 Aug 2025
RapVerse introduces the first dataset for generating rap vocals and full-body motion from text—pushing AI into the future of performance art.

A Single Prompt Will Have This AI Rapping and Dancing
7 Aug 2025
Generate singing vocals and 3D human motions directly from lyrics with RapVerse, a unified AI framework that sets new benchmarks in multimodal generation.

What It Takes to Train a Versatile Speech AI System
20 Jun 2025
Explore the key tasks used to train our speech AI model—from transcription and translation to emotion, sentiment, and speaker detection.