

Table of Links
2 Approach
2.2 Multimodal Instruction Finetuning
2.3 Curriculum Learning with Parameter Efficient Finetuning
4 Results
4.1 Evaluation of SpeechVerse models
4.2 Generalization Across Instructions
4.3 Strategies for Improving Performance
6 Conclusion, Limitations, Ethics Statement, and References
A Appendix
A.1 Audio Encoder Pre-training
5 Related Work
Multi-task learning. Prior studies have shown that a single deep learning model is capable of jointly learning multiple large-scale tasks across different domains [42]. The key idea in multi-task learning is to leverage shared representations across related tasks to improve overall generalization and efficiency. Following this approach, the T5 model [43] frames all text tasks as text-in to text-out, using a unified text-based framework that facilitates shared representations across textual tasks. Similarly, SpeechNet [44] and SpeechT5 [19] leverage a shared encoder-decoder framework to jointly model speech and text modalities spanning 5 to 6 tasks like TTS, ASR, and Voice Conversion (VC). VIOLA [15], a single auto-regressive Transformer decoder-only network, unifies various cross-modal speech and text tasks as a conditional codec language model via multi-task learning. Whisper [20] also employs large-scale multi-task learning, training on related speech tasks including language identification, speech recognition, and translation. In this work, SpeechVerse utilizes multi-task
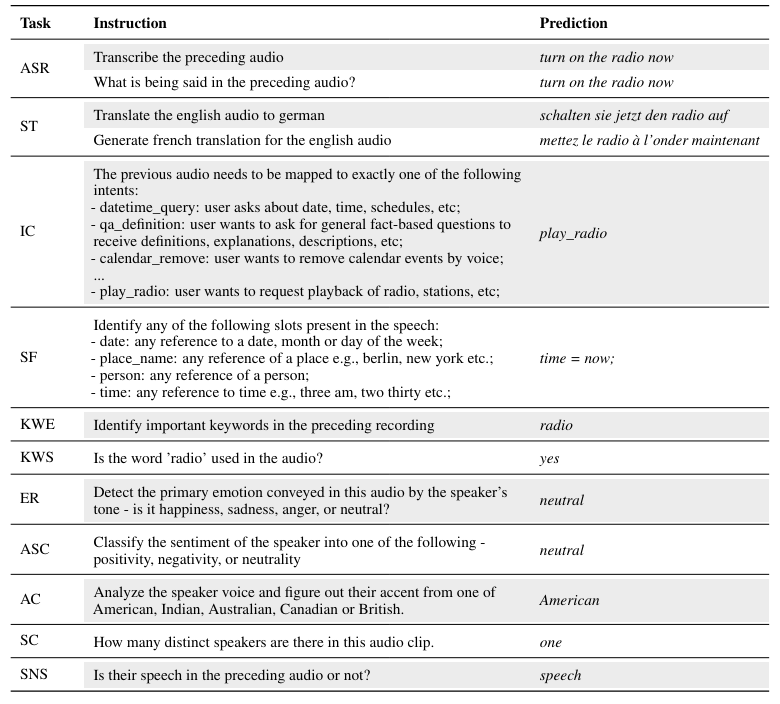
training to transfer knowledge between several related tasks while using natural language instructions to perform each task. Unlike prior work that generated text, speech, or both, our method focuses solely on producing textual output, while taking in audio and text instructions.
Multimodal Large Language Models. Prior work on multimodal LLMs has focused primarily on tasks involving images, such as image generation, visual question answering, and image captioning [4, 9, 45, 46]. Multimodal models incorporating modalities like audio and speech have received relatively less attention compared to vision-and-language models [47–49]. However, there has been growing interest in augmenting large language models with audio data, leading to several proposed approaches [8, 14, 17, 18, 50–52]. SpeechGPT [18] proposed a multimodal LLM combining discrete units of HuBERT with an LLM to solve few understanding tasks like ASR, Spoken QA as well as generation tasks like TTS. [17] introduces the novel capability of zero-shot instruction-following for more diverse tasks such as dialog generation, speech continuation and Question Answering. Most recently, [16] proposed Qwen-Audio, a large-scale audio-language model trained using a multi-task learning approach to handle a diverse range of tasks across various audio types including human speech, natural sounds, music, and songs. Qwen-Audio employs a single audio encoder to process various types of audio whose initialization is based on the Whisper-large-v2 model [20] and performs full finetuning. In contrast, our work utilizes two frozen pretrained models, one each for speech encoder and text decoder to retain their intrinsic strengths. Also, we utilize 30+ instructions for each task during training for improved generalization whereas [17] uses a single fixed instruction. Additionally, SpeechVerse incorporates multi-task learning and instruction finetuning in a single training stage.
Authors:
(1) Nilaksh Das, AWS AI Labs, Amazon and Equal Contributions;
(2) Saket Dingliwal, AWS AI Labs, Amazon([email protected]);
(3) Srikanth Ronanki, AWS AI Labs, Amazon;
(4) Rohit Paturi, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Jie Yuan, AWS AI Labs, Amazon;
(8) Dhanush Bekal, AWS AI Labs, Amazon;
(9) Xing Niu, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Karel Mundnich, AWS AI Labs, Amazon;
(13) Monica Sunkara, AWS AI Labs, Amazon;
(14) Daniel Garcia-Romero, AWS AI Labs, Amazon;
(15) Kyu J. Han, AWS AI Labs, Amazon;
(16) Katrin Kirchhoff, AWS AI Labs, Amazon.
This paper is