
Authors:
(1) Nilaksh Das, AWS AI Labs, Amazon and Equal Contributions;
(2) Saket Dingliwal, AWS AI Labs, Amazon([email protected]);
(3) Srikanth Ronanki, AWS AI Labs, Amazon;
(4) Rohit Paturi, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Jie Yuan, AWS AI Labs, Amazon;
(8) Dhanush Bekal, AWS AI Labs, Amazon;
(9) Xing Niu, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Karel Mundnich, AWS AI Labs, Amazon;
(13) Monica Sunkara, AWS AI Labs, Amazon;
(14) Daniel Garcia-Romero, AWS AI Labs, Amazon;
(15) Kyu J. Han, AWS AI Labs, Amazon;
(16) Katrin Kirchhoff, AWS AI Labs, Amazon.
Table of Links
2 Approach
2.2 Multimodal Instruction Finetuning
2.3 Curriculum Learning with Parameter Efficient Finetuning
4 Results
4.1 Evaluation of SpeechVerse models
4.2 Generalization Across Instructions
4.3 Strategies for Improving Performance
6 Conclusion, Limitations, Ethics Statement, and References
A Appendix
A.1 Audio Encoder Pre-training
Abstract
Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pretrained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model’s capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
1 Introduction
Large language models (LLMs) [1–3] have achieved remarkable performance on a variety of natural language tasks through self-supervised pre-training on massive text corpora. They have also shown a striking ability to follow open-ended instructions from users through further instruction tuning [4–7], enabling strong generalization capabilities. Despite the success, a significant limitation lies in the inability of language models to perceive non-textual modalities such as images and audio.
Speech in particular represents the most natural mode of human communication. Empowering LLMs to deeply understand speech could significantly enhance human-computer interaction [8] and multimodal dialog agents [9, 10]. As such, enabling LLMs to comprehend speech has received
substantial attention recently. Some approaches first transcribe speech via an automated speech recognition (ASR) system and then process the text with an LLM for improved transcription [11–13]. However, such pipelines cannot capture non-textual paralinguistic and prosodic features like speaker tone, intonation, emotion, valence, etc.
A promising new paradigm directly fuses textual LLMs with speech encoders within an end-toend training framework [14, 15]. Enabling joint modeling of speech and text holds promise for richer speech and audio comprehension versus text-only methods. Particularly, instruction-following multimodal audio-language models [16–18] are increasingly receiving more attention due to their generalization capability. Despite some success, existing works in multi-task audio-language models such as SpeechT5 [19], Whisper [20], VIOLA [15], SpeechGPT [18], and SLM [17] are limited to processing a small number of speech tasks.
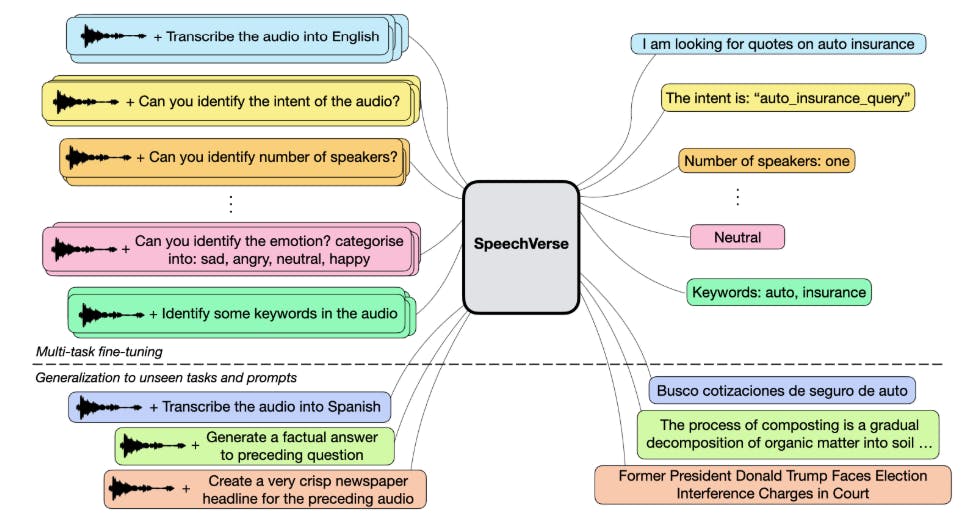
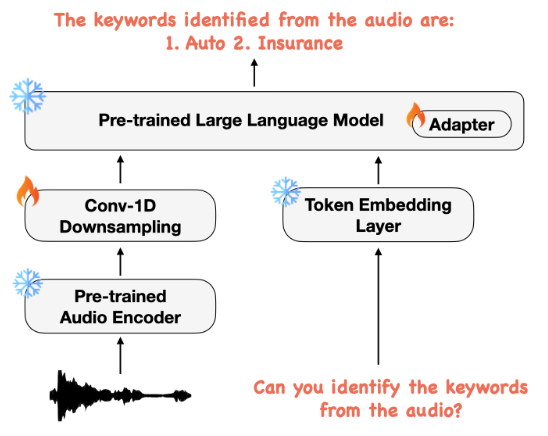
We therefore propose SpeechVerse, a robust multi-task framework that leverages supervised instruction finetuning to incorporate various speech tasks (see Figure 1). In contrast to SpeechGPT [18], we propose using continuous representations extracted from a self-supervised pre-trained speech foundation model, focusing on tasks that generate text-only output. More recently, [16] proposed Qwen-Audio, a multi-task audio-language model capable of perceiving human speech and sound signals and is trained on 30 tasks from diverse audio types including music and songs. However, this requires carefully designed hierarchical tagging and a large-scale supervised audio encoder for fusion making it sub-optimal for unseen speech tasks. In contrast, our training paradigm incorporates multi-task learning and supervised instruction finetuning in a unified curriculum, without the need for task-specific tagging, allowing for generalization to unseen tasks using natural language instructions.
We summarize our contributions below:
-
Scalable multimodal instruction finetuning for diverse speech tasks. SpeechVerse is a novel LLM-based audio-language framework to scalably exhibit strong performance on as many as 11 diverse tasks. We extensively benchmark our models on public datasets spanning ASR, spoken language understanding and paralinguistic speech tasks.
-
Versatile instruction following capability for novel open-ended tasks. We demonstrate the SpeechVerse model’s capability to leverage the robust language understanding of the LLM backbone in order to adapt to open-ended tasks that were unseen during multimodal finetuning.
-
Strategies for improving generalization to unseen tasks. We further study prompting and decoding strategies including constrained and joint decoding, that can enhance the model’s ability to generalize to completely unseen tasks, improving absolute metrics by up to 21%.
This paper is