

Table of Links
2 Approach
2.2 Multimodal Instruction Finetuning
2.3 Curriculum Learning with Parameter Efficient Finetuning
4 Results
4.1 Evaluation of SpeechVerse models
4.2 Generalization Across Instructions
4.3 Strategies for Improving Performance
6 Conclusion, Limitations, Ethics Statement, and References
A Appendix
A.1 Audio Encoder Pre-training
A.1 Audio Encoder Pre-training
Our audio encoder is a 24-layer Conformer model with feature dimension of 768 and attention head of 8. The total number of parameters of this encoder model is 300M. We adopt the BEST-RQ [33] method, which pre-trains the model to predict the masked speech signals with labels generated from a random-projection quantizer. The quantizer projects the speech inputs with a randomly initialized matrix, and performs a nearest-neighbor lookup in a randomly-initialized codebook. Neither the projection matrix nor the codebook is updated during pre-training. We build an internal pre-training dataset containing 300K hours English audios. The pre-training uses mask span of 10 with total effective masking ratio about 40%. The learning rate schedule follows the transformer learning rate schedule with peak value of 0.0005 and warm-up of 50K steps. AdamW optimizer is adopted with weight decay of 0.01. Since the encoder has 4 times temporal-dimension reduction, the quantization with random projections stacks every 4 frames for projections. We use 16 individual codeboooks, where the vocab size of each codebook is 8192 and the dimension is 16. The model is pre-trained for 500K steps in total.
A.2 Hyper-parameters
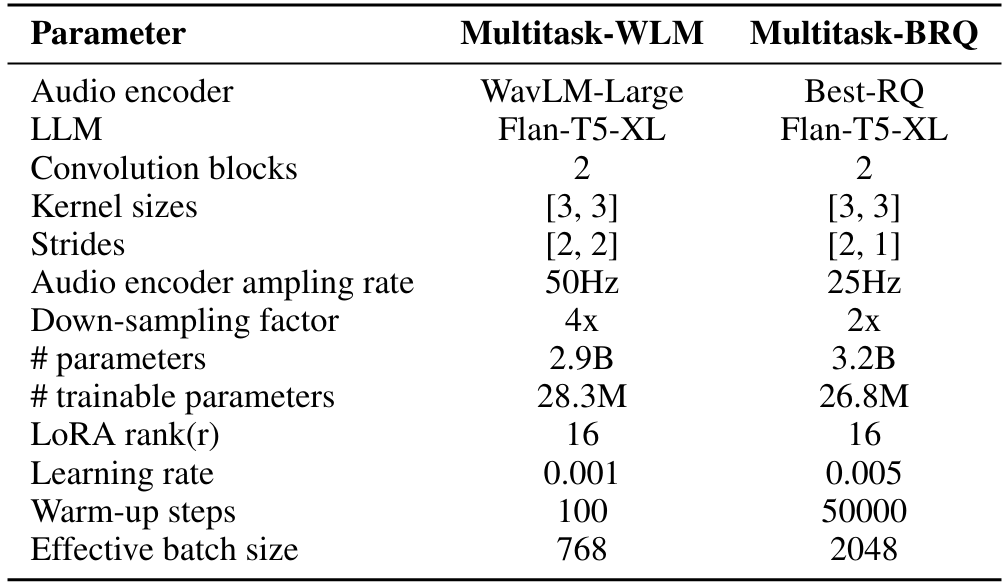
We train all our models on a cluster of machines with 8 A100 GPUs, each having 40GB of memory. Pytorch Lightning framework[3] is used for our implementation. A 5% subset of the complete training dataset for a model is used as a validation set to choose the important hyper-parameters. For the multitask models, the sample weights for each dataset are also chosen using this validation set. Further, all models are trained till the validation loss converges and it does not improve for 5 consecutive epochs. The details of the learning rate, warmup steps, batch size for the Multitask-WLM and Multitask-BRQ are summarized in the Table 11. To adhere to memory constraints of the GPUs, we filter out any training sample where the sequence length of the audio is greater than 900 or the target label is greater than 600. Since, the WavLM Large samples audio features at 50Hz rate, we use two successive 1-D convolution blocks (kernel size=3, stride=2) for the Task-FT and Multitask-WLM model to downsample the audio four times and achieve the desired sampling rate of 12.5Hz. For BestRQ-based audio encoder, the sampling rate is 25Hz and hence the stride of the second convolution block is set to 1 to ensure the output sampling rate is 12.5Hz.
Authors:
(1) Nilaksh Das, AWS AI Labs, Amazon and Equal Contributions;
(2) Saket Dingliwal, AWS AI Labs, Amazon([email protected]);
(3) Srikanth Ronanki, AWS AI Labs, Amazon;
(4) Rohit Paturi, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Jie Yuan, AWS AI Labs, Amazon;
(8) Dhanush Bekal, AWS AI Labs, Amazon;
(9) Xing Niu, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Karel Mundnich, AWS AI Labs, Amazon;
(13) Monica Sunkara, AWS AI Labs, Amazon;
(14) Daniel Garcia-Romero, AWS AI Labs, Amazon;
(15) Kyu J. Han, AWS AI Labs, Amazon;
(16) Katrin Kirchhoff, AWS AI Labs, Amazon.
This paper is