

Table of Links
2 Approach
2.2 Multimodal Instruction Finetuning
2.3 Curriculum Learning with Parameter Efficient Finetuning
4 Results
4.1 Evaluation of SpeechVerse models
4.2 Generalization Across Instructions
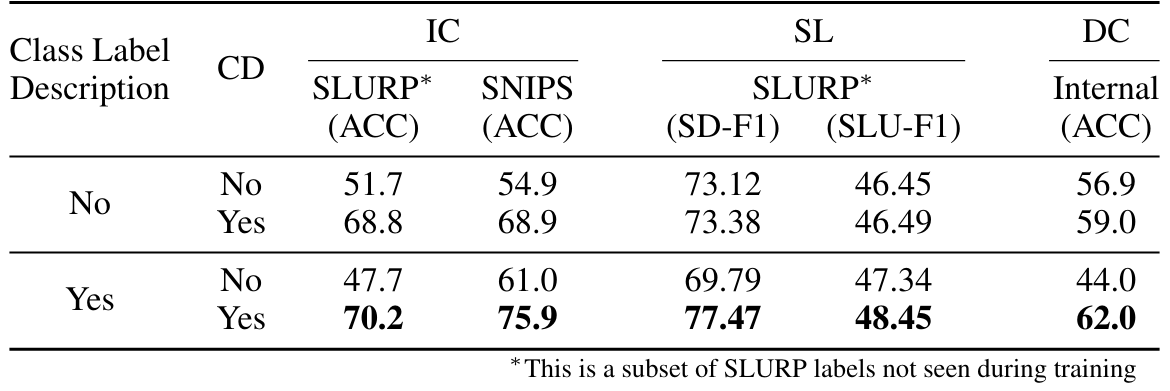
4.3 Strategies for Improving Performance
6 Conclusion, Limitations, Ethics Statement, and References
A Appendix
A.1 Audio Encoder Pre-training
4.2 Generalization Across Instructions
We comprehensively study our Multitask-WLM model’s ability to generalize to diverse forms of unseen instructions. As a first, we try to accomplish seen tasks with differently worded instructions than those used for training. We create novel prompts for some of the training tasks and evaluate the robustness of the model to variations in the prompt. Next, we demonstrate the model’s potential to leverage the robust language understanding of the underlying LLM to generalize to completely new tasks that the model has not seen at all during multimodal finetuning.
4.2.1 Measuring robustness to prompt variations
To evaluate the effect of different prompts on the training task performance, we tested our MultiTaskWLM model with additional prompts for 3 different tasks: ASR, ST and AC. We test with three prompts per task, where one is directly taken from the set of prompts used during training, while two additional novel prompts are created by using a different wording and context. As showcased in the Table 5, the model showecased similar performance across prompts for each task. For the ASR task, we only see a minor variation of 0.3 in WER between seen and unseen prompts. Similarly for the ST and the AC task, the metric values deviates very little with the change in prompt. These small differences indicate that our model has generalized its core capabilities well and is not strongly dependent on the specific wording or context of the prompts. While prompt engineering remains important for optimal performance, these results suggest that the model has learned robust task-specific skills that transfer across the choice of prompts, at least for the tasks seen during training. For the tasks beyond those seen during training, we study the prompt design separately in a later subsection 4.3.1.
4.2.2 Open-ended Instruction Following
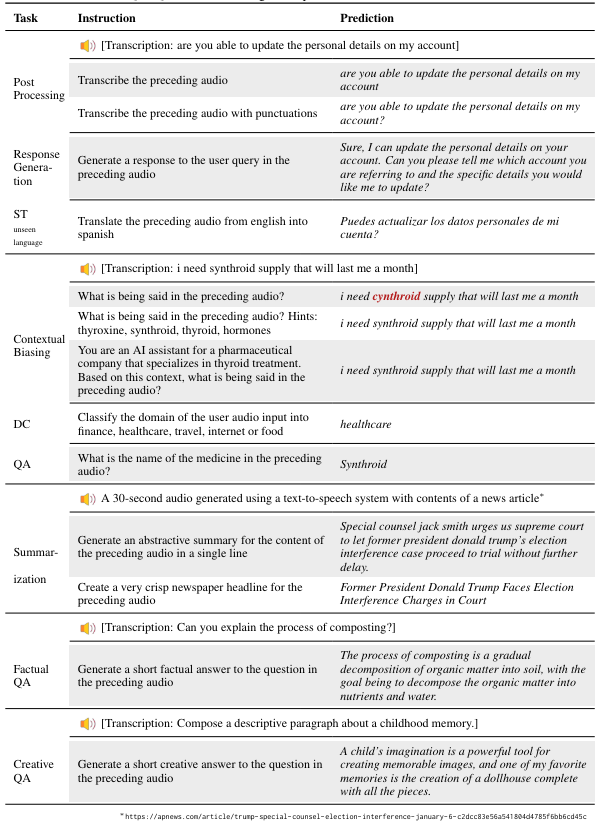
To study the model’s ability to understand open-ended text-based as well as speech-based instructions, we prompted the model with several unrestricted creative requests that were not a part of our training curriculum. We enumerate several such examples in the Table 6. In many of these examples, the model is required to exhibit profound comprehension of both the spoken and written directives to successfully execute the task. For example, in the Creative QA task, the model has to understand the spoken request as well as the instruction prompt in order to generate a related response. In the Summarization task, the model has to correctly surmise the spoken content to generate a summary. In the Contextual Biasing task, we observe that the model is even able to correct its own output when provided with hints. The robust responses of the multi-task model with such a distributional shift in the input from the training data demonstrates the adaptability of its core instruction following skills. Rather than overfitting to the training domain, the multi-task learning approach enables the model to learn more versatile capabilities in instruction comprehension and execution that better transfer to new contexts. We provide some quantitative results on unseen tasks and labels in the next section.
Authors:
(1) Nilaksh Das, AWS AI Labs, Amazon and Equal Contributions;
(2) Saket Dingliwal, AWS AI Labs, Amazon([email protected]);
(3) Srikanth Ronanki, AWS AI Labs, Amazon;
(4) Rohit Paturi, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Jie Yuan, AWS AI Labs, Amazon;
(8) Dhanush Bekal, AWS AI Labs, Amazon;
(9) Xing Niu, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Karel Mundnich, AWS AI Labs, Amazon;
(13) Monica Sunkara, AWS AI Labs, Amazon;
(14) Daniel Garcia-Romero, AWS AI Labs, Amazon;
(15) Kyu J. Han, AWS AI Labs, Amazon;
(16) Katrin Kirchhoff, AWS AI Labs, Amazon.
This paper is